Automate
At Luminide, we are working hard to build a platform that will revolutionize AI development. In this post, we are excited to share details about how Luminide makes it easier to build better AI models.
Can the perspiration phase of AI development be automated? We would all like the answer to be yes. The extent of automation is a good indicator of the maturity of a field. While Deep Learning has made spectacular strides over the past 10 years, its practitioners are keenly aware that the “1% inspiration and 99% perspiration” rule still holds.
AI has been instrumental in automating a myriad of other fields. Strangely, AI has been less successful in automating itself.
Don’t take our word for it. See exhibit A below.
We know what you are thinking. That tweet is from 8 years ago. Back then Andrej was still working on his PhD thesis. Surely things have improved since then?
Apparently not… See exhibit B.
(Add titles somewhere)
As the director of AI and Autopilot at Tesla Motors, Andrej has nearly unlimited resources at his disposal. Most of us have to make do with considerably less firepower. It is no wonder that we feel Andrej’s pain more acutely.
Has there been progress in lessening this pain? Definitely yes. The hardware has become much faster. Abstraction layers have made GPUs easy to use. Data scientists rarely do calculus by hand anymore, instead leaving the differentiation to frameworks such as PyTorch. There are excellent libraries available for common tasks - timm for image classification, detectron2 for detection and segmentation, SpeechBrain for speech recognition, MONAI for medical imaging, Hugging Face Transformers for NLP - the list goes on and on. Why are data scientists still spending a lot of their time on activities that are not exactly data science?
Mainly a combination of two factors:
The appetite of neural networks for computing resources continues to outpace advances in hardware. While Moore’s law has been faithfully pushing compute throughput ever higher, the neural networks have grown even more demanding. Training a SOTA neural network is getting more and more expensive in terms of both time and money.
The training process must be repeated several times to optimize the hyperparameters of the model. This iterative nature of AI development has a multiplicative effect on 1 above. Devising a network architecture and setting up a data pipeline to train it is only a small part of the model building process.
As for 1, we have to expect this trend to continue because the dimension that SOTA primarily optimizes for is model quality and not resource usage. And rightfully so… After all, if you are building a model to solve a high-value problem in self driving or drug discovery, your main concern would be how well the model generalizes. We consider 1 as essential complexity.
The iterative development process however, is amenable to automation. At Luminide, we consider it our mission to eliminate unnecessary complexity that lurks in the model building process. In order to avoid babysitting chores that data scientists typically perform, we want the system to intelligently mimic their actions. This includes applying intuition, using judgment and making decisions - admittedly challenging tasks for a non-human.
Tuning a model typically requires repeatedly training it with different sets of hyperparameter values while searching for values that maximize generalizability. Training to completion is often expensive in terms of time and money. In order to speed up the process and keep costs low, data scientists may choose to partially train their models and use their intuition to extrapolate the results.
As an example, take the following scenario where we compare two hypothetical trials. Trial 1 and trial 2 represent training sessions with different sets of hyperparameters.
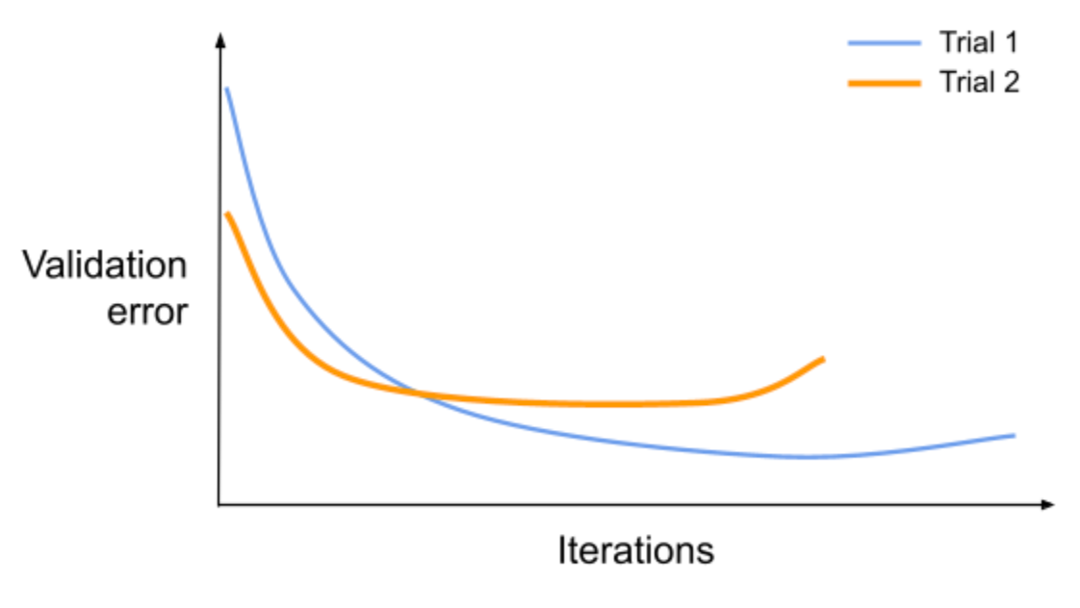
As an example, take the following scenario where we compare two hypothetical trials. Trial 1 and trial 2 represent training sessions with different sets of hyperparameters.
Copyright © 2022 Luminide, Inc. All rights reserved.