Background
Dec 2021 by Luke Hornof and Anil Thomas
The motivation for Luminide came from our own personal experience over the past 10 years building technologies that span the entire AI hardware-software stack. We were two of the first employees at Nervana, an AI accelerator startup, which was later acquired by Intel. We developed AI algorithms, frameworks (before TensorFlow or Pytorch existed), compilers, GPU kernels, and drivers. We published numerous papers and were granted multiple patents. [1,2]
We have the most experience, however, with building AI models. We built numerous AI models across a wide variety of domains including energy, underwater exploration, and agriculture. Anil even achieved Kaggle grandmaster status, indicating he’s one of the top model designers in the world.
During this time we used a lot of great tools for model development. Some of our favorites include PyTorch, Scikit, Jupyter notebooks, CuDNN, and GPUs. But there was always one tool missing -- a simple, unified IDE for AI model development. This page explains why such a tool is needed and how we're building it.
Data scientists should spend their time doing data science
While building AI models, we were frustrated with all the time we were spending on everything but data science. This includes doing our own DevOps -- downloading libraries, installing drivers, navigating complex dashboards, troubleshooting issues. And repeating the same tedious tasks over and over again -- running numerous experiments, recording hyperparameters, tracking code changes, searching through log files.
Model complexity gap
As models grew larger and more complex, we also ran into the same time and cost issues as the rest of the industry, something we call the model complexity gap. While hardware performance is following Moore’s law and doubles every 18 months, in that same time model complexity increases 35x. The time estimate to train a large model such as GPT-3 with 175 billion parameters is 355 years of GPU time, and the cost estimate ranges from $4.6-12M [3,4]. This gap will just continue to grow over time.
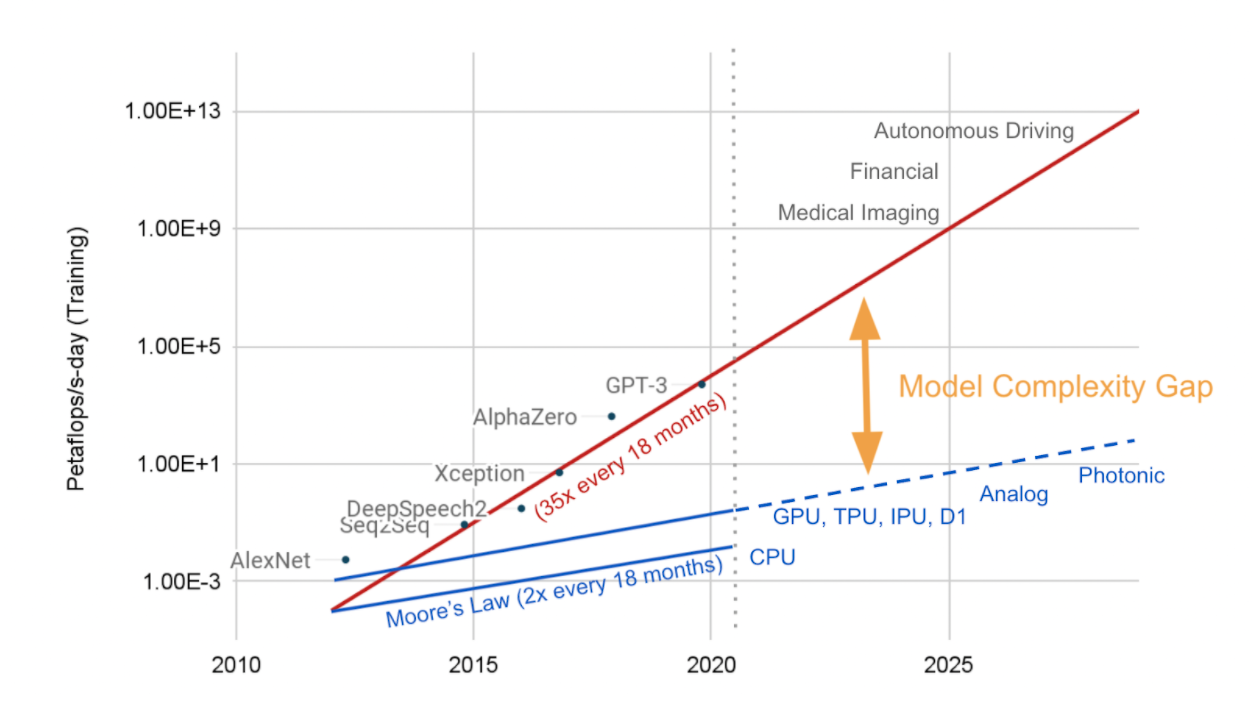
Simply scaling hardware won’t work because it not only drives the price sky high, but it results in a large carbon footprint. Studies show that training a state-of-the-art NLP model emits over 78,000 pounds of carbon emissions, equivalent to 125 round-trip flights between New York and Beijing. [5,6]
Therefore, software solutions will be an essential piece to solving this puzzle. [7] The fundamental challenge is how to achieve the same model accuracy with less computation. This will save time and money locally, and reduce the carbon footprint globally.
A Simple, Unified IDE for Model Development
We heard our sentiments echoed by data scientists around the world. We eagerly anticipated new tools as they were released, but none offered an elegant solution meeting our needs:
Focus on model development: Instead, there were generic end-to-end platforms, one-size-fits-all solutions, or tools for other aspects of the data science lifecycle.
Uniformity: There were lots of great tools and libraries out there -- code editors, notebooks, open-source libraries, and standalone tools. But they required downloading software, managing dependencies, navigating complicated dashboards, or installing hardware and drivers.
Simplicity: Getting started with a monolithic, enterprise platform is a daunting task. It takes significant time to learn and use a new ecosystem.
This is why we built Luminide, a simple, unified IDE for model development. The Luminide IDE was designed bottom-up specifically for model development. Whether starting with an existing, state-of-the-art model or designing one from scratch, Luminide streamlines and accelerates the development process. Experiment to see if new layers make an improvement. Fine-tune with domain specific data. Hyperparameter tune to get that last bit of accuracy.
Luminide uses as many great, existing open-source software solutions and libraries as possible, e.g. Docker, Kubernetes, PyTorch, TensorFlow, JupyterLab, JupyterHub. Since Luminide handles the integration, data scientists don’t have to. There’s nothing to download or install, no DevOps. Also, with full visibility and control of the model-development process -- code, data, servers, experiments -- tedious, repetitive tasks can be completely automated or made available with a single click.
All of this is immediately accessible to users via a hosted, customized version of JupyterLab, a favorite among data scientists. And even though different processes are running on different machines, everything is neatly displayed in a single GUI that runs in your browser. Think of it as turning your laptop into a supercomputer with unlimited compute power and storage capacity. Or as an always-on IDE, with accelerators attached/detached as needed, leading to reduced compute costs.

Early Ranking
Another advantage of a unified IDE is the ability to design new, more sophisticated optimizations. Dynamic algorithms collect run-time data to increase performance, while distributed optimizations coordinate multiple software processes potentially running on different hardware components.
One dynamic, distributed optimization we developed uses predictive modeling to determine the relative outcome of a training run after only a few epochs. For example, instead of running 30 epochs for a training run, it may only require 3. The result can be used by data scientists to do rapid prototyping and fast hyperparameter tuning. We call this optimization Early Ranking. [8]
The performance gained is complementary to other optimizations. For example, we start with a state-of-the-art Bayesian optimizer and achieve an additional 10x speedup. In a head-to-head hyperparameter tuning comparison, Luminide achieved the same model accuracy in 3 hours that it took the current best-in-class software 30 hours to achieve.
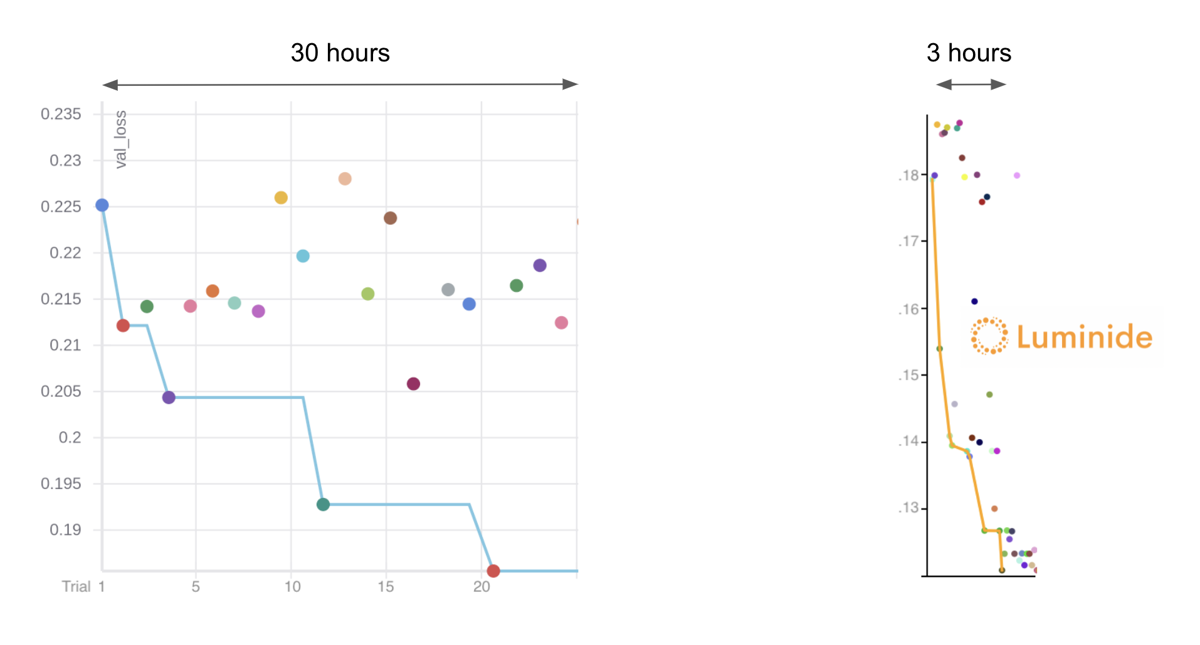
Optimizations like this are complicated, however. Early Ranking requires building a predictive model, using it during training, and collecting additional run-time data to maximum performance. With a unified IDE, all of this happens without any additional effort from the data scientists, such as modifying or instrumenting their code -- exactly the type of burden we’re trying to free the data scientists from.
Looking Ahead
The enthusiastic response we’ve received from early adopters confirms the demand for a simple, unified IDE for model development. Luminide has been used to place Top 1% in live Kaggle competitions and active discussions are underway with healthcare companies and asset managers on how Luminide can help them build more accurate models while reducing their time and costs. [9]
Identifying and prioritizing additional features is guided by feedback from Luminide users as well as ongoing conversations we have with data scientists around the world:
Additional Optimizations: Early Ranking is just the first optimization we’ve implemented. Initial results exploring distributed optimizations for data augmentation and network architecture search are already promising.
Hyperparameter Tuning and AutoML: Despite a lot of promise, hyperparameter tuning and AutoML are still only used by a small fraction of data scientists. [10] One of Luminide’s goals is to make these techniques mainstream.
Security and Privacy: An on-premise version of Luminide will ensure a company’s sensitive data will be protected.
We believe the key to a great AI model development tool is a simple, unified IDE, that is easy to use and enables new powerful, system-wide optimizations. With Luminide, data scientists can focus on data science and together we’ll close the model complexity gap.
Sincerely, Luke and Anil Luminide co-founders
[1] Publications and patents for Luke Hornof [2] Publications and patents for Anil Thomas [3] OpenAI's GPT-3 Language Model: A Technical Overview [4] OpenAI’s massive GPT-3 model is impressive, but size isn’t everything [5] Is ‘Green AI’ the same as environmental AI? [6] Energy and Policy Considerations for Deep Learning in NLP [7] Sustainable AI: Environmental Implications, Challenges and Opportunities [8] Expedited Assessment and Ranking of Model Quality in Machine Learning, USPTO Application 17560422, December 2021. [9] Kaggle: Plant Pathology 2021 - FGVC8. Part of the Computer Vision and Pattern Recognition Conference CVPR 2021. [10] Kaggle: State of Data Science and Machine Learning 2021
Copyright © 2022 Luminide, Inc. All rights reserved.