Better Automation for Higher Accuracy AI Models
Apr 2022 by Anil Thomas
At Luminide, we are working hard to build a platform that will revolutionize AI development. In this post, we are excited to share some details with you.
Automating the Perspiration Phase
The extent of automation is a good indicator of the maturity of a field. While Deep Learning has made spectacular strides over the past 10 years, its practitioners are keenly aware that the “1% inspiration and 99% perspiration” rule still holds.
AI has been instrumental in automating a myriad of other fields. Strangely, AI has been less successful in automating itself. Don’t take our word for it. See exhibit A below.
This tweet is from 8 years ago, back when Andrej was still working on his PhD thesis. Surely things have improved since then? Apparently not… See exhibit B.
As the director of AI and Autopilot at Tesla Motors, Andrej has nearly unlimited resources at his disposal. Most of us have to make do with considerably less firepower, so we feel Andrej’s pain even more acutely.
Has there been progress in improving the model building workflow? Definitely yes. The hardware has become much faster. Abstraction layers have made GPUs easy to use. Data scientists rarely do calculus by hand anymore, instead leaving the differentiation to frameworks such as PyTorch. There are excellent libraries available for common tasks – timm for image classification, detectron2 for detection and segmentation, SpeechBrain for speech recognition, MONAI for medical imaging, Hugging Face Transformers for NLP – the list goes on and on.
Why do data scientists often still spend a lot of their time on activities that are not data science? Mainly a combination of two factors:
- Increased compute demand: The appetite of neural networks for computing resources continues to outpace advances in hardware. While Moore’s law has been faithfully pushing compute throughput ever higher, the neural networks have grown even more demanding. Training a State Of The Art (SOTA) neural network is getting more and more expensive in terms of both time and money.
- Necessary iteration: The training process must be repeated numerous times. First while designing the model itself, along with additional tasks like data augmentation, and when optimizing the hyperparameters of the model.
As for increased compute demand, we expect this trend to continue.The dimension that SOTA primarily optimizes for is model quality and not resource usage. And rightfully so… After all, if you are building a model to solve a high-value problem in autonomous driving or drug discovery, your main concern would be how well the model generalizes. We consider this essential complexity. The iterative development process however, is amenable to automation.
Automating Intuition
At Luminide, we consider it our mission to eliminate unnecessary complexity that lurks in the model building process. In order to avoid babysitting chores that data scientists typically perform, we want the system to intelligently mimic their actions. This includes applying intuition, using judgment and making decisions - admittedly challenging tasks for a non-human.
Tuning a model typically requires repeatedly training it with different sets of hyperparameter values while searching for values that maximize generalizability. Training to completion is often expensive in terms of time and money. In order to speed up the process and keep costs low, data scientists may choose to partially train their models and use their intuition to extrapolate the results.
As an example, take the following scenario where we compare two hypothetical trials. Trial 1 and trial 2 represent training sessions with different sets of hyperparameters.
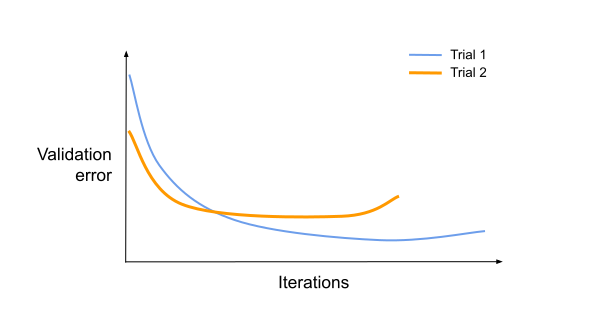
Both trials were run to completion, letting us clearly see which one led to superior results (trial 1). What if they were stopped long before the models actually converged?
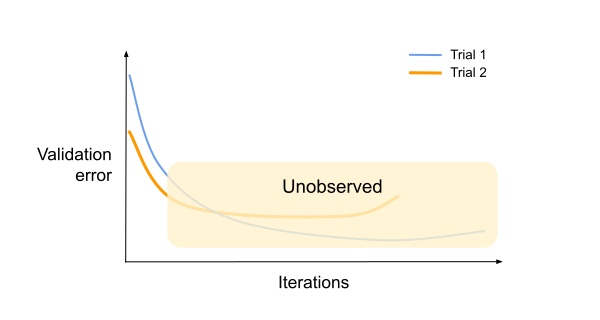
In this case, to pick the eventual winner, we need more than the observed validation error at the end of each partial trial. An experienced data scientist might notice that the validation error curve of trial 1 has a steeper gradient than that of trial 2. They might also look at the training error curves for additional insight.
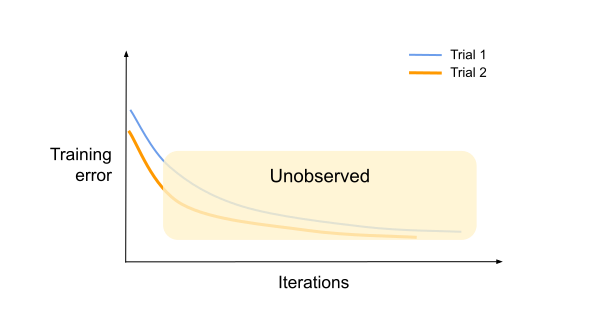
The lower training error for trial 2 could imply a quicker overfit if allowed to run to completion. Taking all this into account, the data scientist might correctly pick trial 1 as the winner.
Codifying this intuition is the key to automating the tuning process. In real life, the observed curves are rarely as smooth as the ones shown. Also, the eventual outcome of a trial may depend on many other factors. For example, a trial where the training error diverges from validation error at a relatively higher rate might indicate a tendency to overfit. How can a system rank trials given noisy features from partial evaluations? Our solution was to build a machine learning model that performs the ranking. We have trained this model with data collected from complete training sessions over multiple tasks and datasets. We have already deployed this model for use with Luminide. We continue to improve the quality of our model by fine-tuning it with more and more data. Feel free to sign-up and give it a try.
Focus on High Accuracy
While every stage in the machine learning pipeline is important to the success of an AI project, the model building stage (which involves a lot of iterative designing and tuning) can really make or break a project. There is often a performance threshold that the model must cross before it can move on to the deployment stage. If you are building a mammogram analyzer, the model must outperform the consensus of multiple radiologists. For a self-driving car, a model might need to display manyfold improvement over the skill of an average human driver. By enabling rapid iteration, Luminide improves the chances of crossing this threshold. In the next section, we show you a case study on using Luminide to solve a multi-label classification problem that was published as a CVPR workshop challenge.
Case Study: CVPR Plant Pathology Competition
Despite advances in AutoML, Kaggle competitions continue to be won by solutions that are painstakingly built and tuned by hand. We designed Luminide to automate as much of the model building pipeline as possible.
The steps to build a model may look like this:
Create code for the task at hand
Connect the code to the dataset and compute infrastructure
Train, validate and perform sanity checks on the initial model
Apply ingenuity for any custom work needed
Tune the model
Produce the final version of the model with the tuned hyperparameters
Except for step 4, all other steps can be automated.
Automating everything… except ingenuity
To illustrate, we will use this computer vision problem: Plant Pathology Challenge, CVPR 2021. The task is to classify the leaf images as healthy or unhealthy and further classify the type of disease if unhealthy.
We used Luminide to automate the entire training/tuning process – from importing the dataset to running inference on the test dataset with a well-tuned model – all with a few button clicks. The following steps describe how you can reproduce this process.
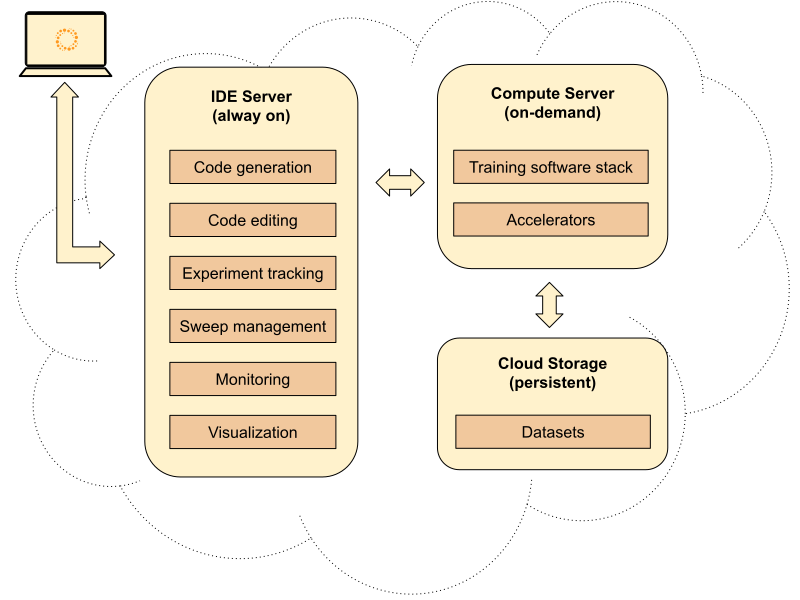
High level architecture of Luminide. Users interact with the cloud-based IDE Server using a web browser such as Google Chrome.
Luminide hosts pre-made templates that can be used to generate source code for common tasks such as image classification and segmentation. After you log into the Luminide IDE Server, you can either import source code from existing repositories, create and edit source code using the built-in editor or simply choose a template from which to automatically generate code.
You can edit the code and compile it on the IDE Server without having to attach a Compute Server. When you are ready to try out the code, pick a server from the many Cloud Service Providers that we support. When you attach a Compute Server for the first time, the system also provisions persistent cloud storage.
Next, import the dataset for this project using the “Import Data” menu. The datasets that you import will continue to exist on cloud storage even after you detach a Compute Server. The same storage gets mounted automatically the next time you attach a Compute Server. Once you have the dataset downloaded, you might want to run the EDA (Exploratory Data Analysis) notebook that is part of the automatically generated source code. Use this notebook as a starting point to analyze the label distribution and view data examples.
At this point, you are ready to run your first Luminide experiment. Launch a training session to copy over the code to the Compute Server, execute it there and copy the results back.
Once the model is trained, invoke the reporting notebook to analyze the model output and get a better understanding of how well it works. Using the same dataset as the one in the tutorial yields a validation loss of 0.1071. In the next section, we’ll look at improving the accuracy of the model with fast, automated tuning.
Fast hyperparameter tuning
In lieu of manually modifying hyperparameters, retraining the model, and watching its progress to come up with better values, there are a number of good libraries like Ray Tune and hyperopt that will automate this process. All of these libraries are compatible with Luminide, and since we’ve had good results with the Optuna optimizer, we’ve integrated this library first.
There are two kinds of sweeps that are supported. In “full sweep” mode, Luminide runs all training sessions (trials) to completion. For this model, a full sweep of 25 trials takes over 3.5 hours.
The “fast sweep” on the other hand, runs a limited number of iterations per trial. The ranking model described earlier assesses the quality of the model after each trial. In practice, this mode is up to 10x faster and achieves results that are comparable to that of a full sweep.
The result of running a fast sweep for 25 trials, which takes less than 45 minutes, is given below:
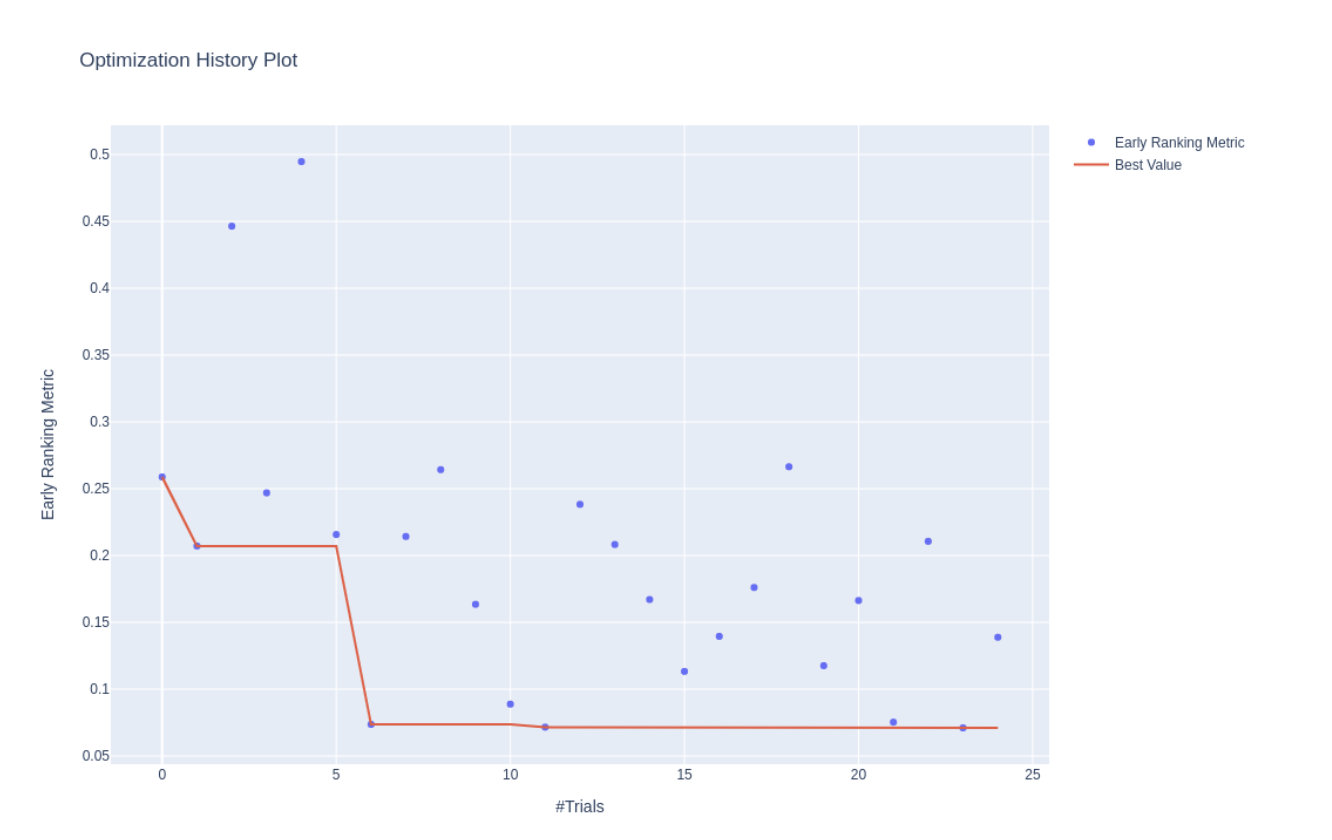
The dashboard above shows how the sweep progressed over the trials. Each trial was run for just 5 epochs (in a full sweep, each would run anywhere between 20 and 60 epochs, due to random number seeds, early stopping, etc.). The Y axis shows the “Early Ranking Metric”. It is different from the validation error at the end of the fifth epoch. Instead, it is meant to correlate with the validation error values if the trials were run to completion. Note that it is only meaningful in relative terms. In other words, the early ranking metric is for comparing trials. We use it to help our blackbox optimizer to intelligently suggest the next set of hyperparameter values to try.
Once your sweep is complete, you can use the tuned configuration to train your final model and achieve a validation loss of 0.0784. Invoke the reporting notebook once again to visualize the results.
Input image

CAM before tuning

CAM after tuning

The final report shows class activation maps on sample images. These are useful to verify that the model is indeed focusing on the right features within the input images.
Kaggle Top 1%
If we compare our initial validation loss with our final loss, we see an improvement of 37%. This additional accuracy could be enough to create a SOTA model or solve a new, open problem. And if we compare the time it takes to perform the fast sweep with the time it takes to do a traditional, full sweep, we see a ~5x improvement.
Validation loss
Before tuning
0.1071
After tuning
0.0784
Improvement
37%
Elapsed time
Full sweep
3 hr 35 min
Fast sweep
40 min
Improvement
5.4x
For this blog, we opted to use a subset of the data with low-resolution images to make it easy for anyone to reproduce these results. For the actual Kaggle competition, in addition to following the steps presented in this blog, we used the original dataset and employed other techniques such as performing 5-fold cross validation and ensembling the results. This combination helped Luminide place 2nd out of 626 teams.
Summary
In this post, we have presented an overview of the newly released Luminide platform. We showed how to build a powerful computer vision model through a case study exploring Luminide's novel and unique aspects:
Entirely auto-generated code
Completely automated tuning
Less than 1 hour of compute time
Zero time spent babysitting
You should be able to follow the strategy outlined in this blog and use Luminide to improve your own model, whether it’s for a Kaggle competition or real-world use. For a limited time we are offering a free trial of Luminide. Please sign up and let us know what you think – we’d love to get your feedback.
Copyright © 2022 Luminide, Inc. All rights reserved.